|
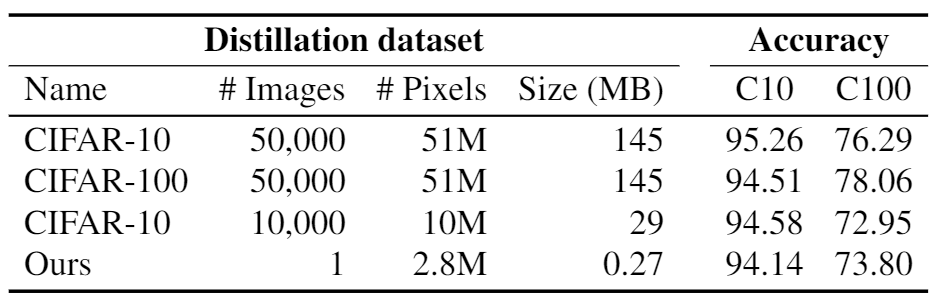
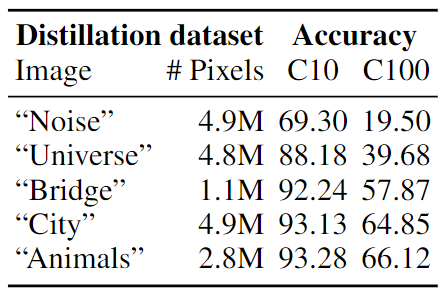
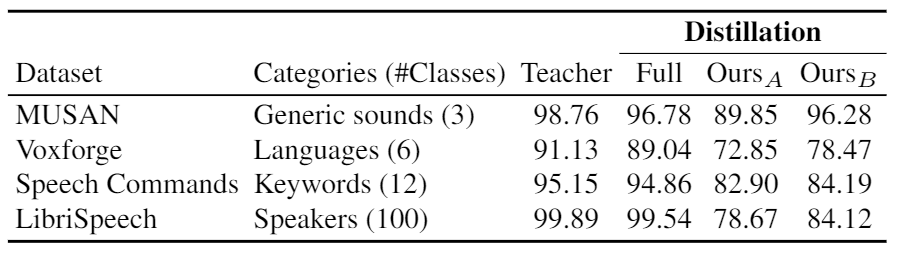
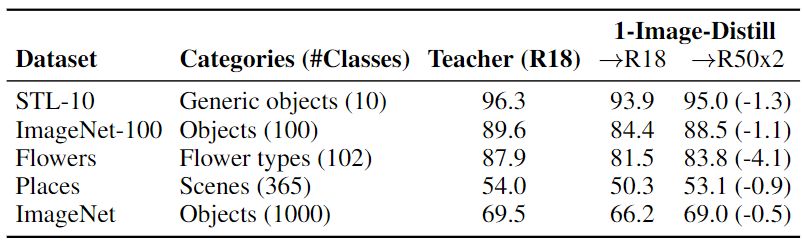
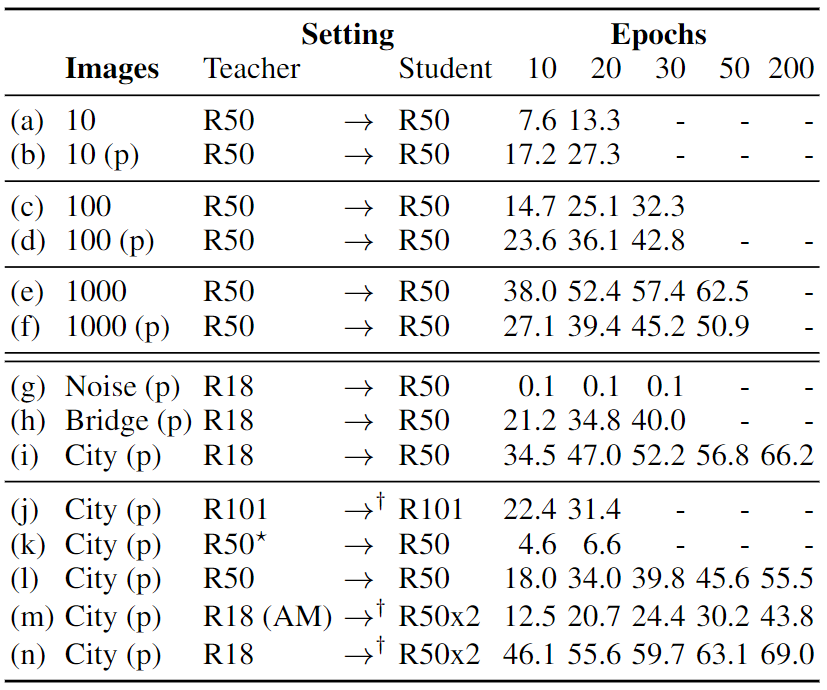
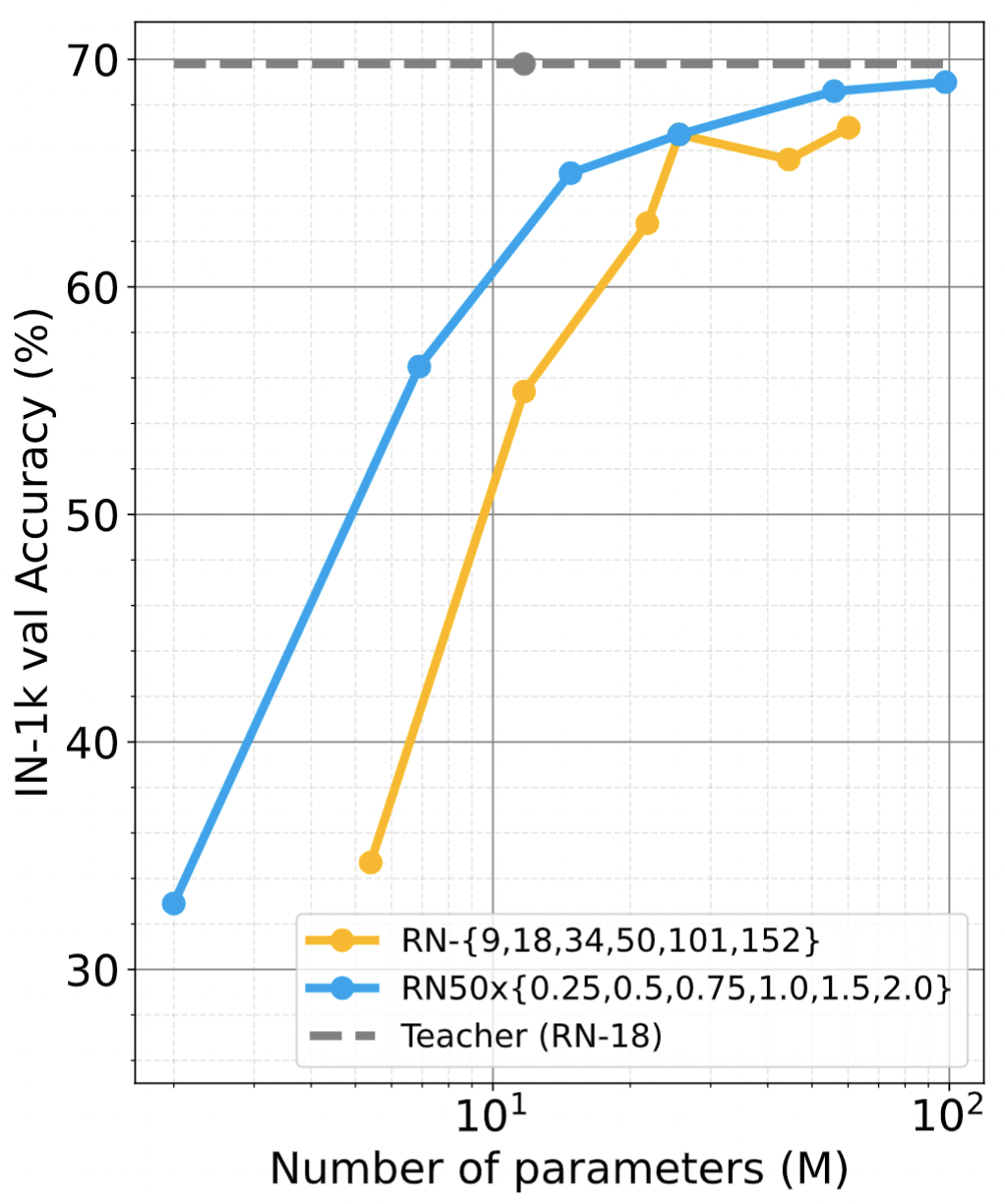
What can neural networks learn about the visual world when provided with only a single image as input? While any image obviously cannot contain the multitudes of all existing objects, scenes and lighting conditions – within the space of all 2563x224x224 possible 224-sized square images, it might still provide a strong prior for natural images. To analyze this augmented image prior hypothesis, we develop a simple framework for training neural networks from scratch using a single image and augmentations using knowledge distillation from a supervised pretrained teacher. With this, we find the answer to the above question to be: surprisingly, a lot. In quantitative terms, we find accuracies of 94%/74% on CIFAR-10/100, 69% on ImageNet, and by extending this method to video and audio, 51% on Kinetics-400 and 84% on SpeechCommands. In extensive analyses spanning 13 datasets, we disentangle the effect of augmentations, choice of data and network architectures and also provide qualitative evaluations that include lucid panda neurons in networks that have never even seen one.
|